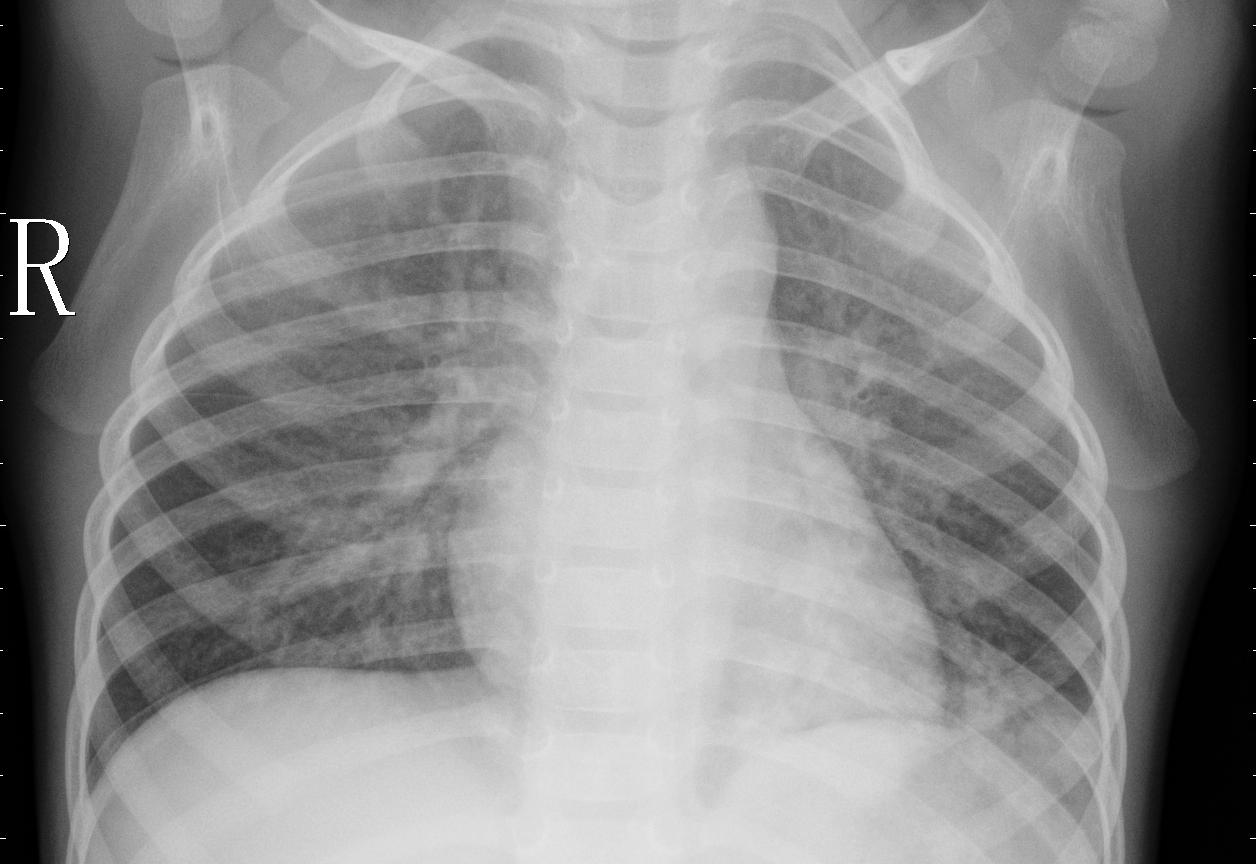
Fundamentação Científica – Diagnóstico de Pneumonia em Radiografias de Tórax
A pneumonia é uma infecção que atinge os pulmões, provocando inflamação nos alvéolos, que podem se encher de líquido ou pus. É uma das principais causas de morbidade e mortalidade no mundo, sendo o diagnóstico precoce essencial para o tratamento eficaz.
Papel da Radiografia de Tórax
A radiografia de tórax é um dos exames mais utilizados na investigação de pneumonia. Ela é relativamente barata, rápida e amplamente disponível, permitindo ao médico observar alterações pulmonares sugestivas da doença.
Sinais Radiográficos Clássicos da Pneumonia
De acordo com a literatura médica, alguns dos sinais mais comuns que um radiologista ou médico observa em uma radiografia de tórax são:
- Opacidades pulmonares: áreas esbranquiçadas na imagem, indicando acúmulo de líquido, secreção ou células inflamatórias.
- Consolidação alveolar: aspecto homogêneo e denso em parte do pulmão, podendo ocupar um lobo ou segmento.
- Broncograma aéreo: visualização dos brônquios cheios de ar cercados por áreas de consolidação (um sinal bastante característico de pneumonia).
- Infiltrados intersticiais: padrões difusos e reticulados, mais comuns em pneumonias virais ou atípicas.
- Assimetria pulmonar: quando um pulmão apresenta alteração evidente em comparação ao outro.
- Derrame pleural associado: em alguns casos, pode haver acúmulo de líquido na pleura, visível como apagamento dos ângulos costofrênicos.
Esses sinais devem ser interpretados em conjunto com o quadro clínico do paciente (tosse, febre, falta de ar, dor torácica), já que alterações semelhantes podem ocorrer em outras doenças (ex.: tuberculose, insuficiência cardíaca, atelectasia).
Relevância para o Projeto de Visão Computacional
Para o cientista de dados que não tem formação médica:
- Classes do dataset (normal x pneumonia) → correspondem, de forma simplificada, a radiografias sem alterações significativas (normal) versus radiografias com os sinais descritos acima (pneumonia).
- O modelo de visão computacional deve aprender a reconhecer padrões de opacidade e consolidação nas imagens.
- Essa base conceitual ajuda a entender por que o algoritmo precisa de milhares de exemplos rotulados: porque os sinais podem ser sutis, variados e até sobrepostos a outras condições.
Referências Acadêmicas Básicas
Para fundamentação científica, destacam-se:
- FELSON, Benjamin. Principles of Chest Roentgenology. 4. ed. Philadelphia: Saunders Elsevier, 2010.
- WEST, John B. Pulmonary Pathophysiology – The Essentials. 9. ed. Philadelphia: Wolters Kluwer, 2017.
- GRAINGER, R. G.; ALLISON, D. J. Grainger & Allison’s Diagnostic Radiology: A Textbook of Medical Imaging. 7. ed. Elsevier, 2020.
📂 Dataset – Chest X-Ray Images (Pneumonia) – Kaggle
Origem do Dataset
O dataset utilizado neste projeto é o Chest X-Ray Images (Pneumonia), disponível publicamente no Kaggle:
🔗 Chest X-Ray Images (Pneumonia) – Kaggle
https://www.kaggle.com/datasets/paultimothymooney/chest-xray-pneumonia
Esse conjunto de dados é amplamente utilizado em pesquisas e projetos de aprendizado de máquina aplicados à saúde, especialmente para treinamento de modelos de Visão Computacional no diagnóstico de pneumonia.
Estrutura do Dataset
O dataset contém um total de 5.856 imagens de raio-X de tórax, já organizadas em diretórios para facilitar o treinamento e a validação de modelos:
chest_xray/
train/
NORMAL/
PNEUMONIA/
val/
NORMAL/
PNEUMONIA/
test/
NORMAL/
PNEUMONIA/
- train/ → imagens usadas para treinamento do modelo.
- val/ → imagens usadas para validação (ajuste de hiperparâmetros, prevenção de overfitting).
- test/ → imagens usadas para teste final e avaliação da performance do modelo.
Cada subpasta contém imagens categorizadas como:
- NORMAL → radiografias sem sinais de pneumonia.
- PNEUMONIA → radiografias de pacientes diagnosticados com pneumonia (podendo incluir pneumonia viral ou bacteriana).
Estatísticas do Dataset
Total de imagens: 5.856
Treinamento (train): Normal: 1.341 imagens / Pneumonia: 3.875 imagens
Validação (val): Normal: 8 imagens / Pneumonia: 8 imagens — essa parte do conjunto de validação é muito pequena para fornecer uma avaliação estável durante o treinamento. Como temos apenas 16 imagens no total para validação, métricas como val_loss e val_accuracy podem variar muito e não refletir completamente a generalização do modelo.
Teste (test): Normal: 234 imagens / Pneumonia: 390 imagens
Observação: o dataset é desbalanceado, com muito mais imagens de pneumonia do que de casos normais. Isso deve ser levado em conta no treinamento, utilizando técnicas como data augmentation, class weights ou oversampling.
Considerações Éticas e de Uso
- O dataset foi publicado no Kaggle para fins de pesquisa e educação.
- Não deve ser usado em ambientes clínicos reais sem validação científica e regulatória.
- É uma excelente base para aprendizado, mas possui limitações: qualidade variável das imagens, possíveis vieses nos diagnósticos originais, e ausência de dados clínicos complementares.
Escolhendo o Modelo e Técnicas Mais Aplicáveis
Objetivo
O objetivo principal do projeto é classificar radiografias de tórax em duas categorias: NORMAL ou PNEUMONIA, com base nos padrões visuais presentes nas imagens. Para isso, é necessário escolher um modelo que consiga extrair características visuais complexas e diferenciar sutilezas entre classes.
Racional para Escolha do Modelo
Rede Neural Convolucional (CNN)
- Por que CNN?
- Radiografias são imagens bidimensionais; padrões visuais (opacidades, consolidações) precisam ser detectados de forma hierárquica e espacialmente sensível.
- CNNs são projetadas para extração automática de características visuais, dispensando engenharia manual de features.
- CNNs já são amplamente aplicadas em diagnóstico assistido por imagem médica, com resultados robustos em pneumonia, câncer de pulmão, e outras doenças.
Transfer Learning (Aprendizado por Transferência)
- Modelos pré-treinados em grandes datasets de imagens (ex.: VGG16, ResNet50, EfficientNet) podem ser adaptados para o nosso problema.
- Vantagens:
- Redução significativa do tempo de treinamento.
- Melhor performance com datasets moderadamente pequenos (como o do Kaggle).
- Aproveitamento de features já aprendidas em imagens gerais, que ajudam na detecção de padrões complexos.
Técnicas Complementares
- Data Augmentation
- Técnicas como rotacionar, inverter, zoom, shift ajudam a aumentar a diversidade do dataset e reduzir overfitting.
- Class Weighting / Oversampling
- O dataset é desbalanceado (muito mais imagens de pneumonia que normais).
- Ajustar pesos de classe ou aplicar oversampling evita que o modelo fique viciado na classe majoritária.
- Pré-processamento de Imagens
- Redimensionamento das imagens para tamanho fixo (ex.: 224×224 pixels).
- Normalização dos pixels para valores entre 0 e 1.
- Conversão para tensores, compatíveis com frameworks de deep learning.
- Funções de Ativação e Otimizadores
- ReLU em camadas ocultas para introduzir não-linearidade.
- Softmax ou sigmoid na saída para classificação binária.
- Adam como otimizador, por sua capacidade de convergência rápida e estável.
- Métricas de Avaliação
- Accuracy: taxa geral de acertos.
- Precision e Recall: importantes em diagnóstico médico, pois penalizam falsos positivos e falsos negativos.
- F1-Score: equilíbrio entre precision e recall.
- ROC-AUC: desempenho global do modelo em diferentes limiares de decisão.
Considerações Finais
- O racional acima não é apenas técnico, mas estratégico e didático: o cientista de dados que queira replicar o projeto entenderá o “porquê” de cada escolha.
- Essa abordagem cria um guia de decisão claro, que pode ser adaptado para outros problemas de classificação de imagens médicas ou de visão computacional.
Pré-processamento e Preparação dos Dados
Objetivo
O pré-processamento é uma etapa essencial para garantir que o modelo receba imagens uniformes e consistentes, melhorando a performance e a capacidade de generalização do modelo.
Etapas do Pré-processamento
- Redimensionamento das imagens
- Todas as imagens do dataset são ajustadas para um tamanho fixo, geralmente 224×224 pixels, compatível com a maioria das arquiteturas CNN e modelos pré-treinados.
- Isso padroniza a entrada e facilita a computação em batches.
- Conversão para escala de intensidade adequada
- As imagens são convertidas para valores normalizados entre 0 e 1, ou seja, cada pixel tem valor contínuo na faixa [0,1].
- Essa normalização ajuda na convergência do modelo durante o treino, evitando problemas com gradientes muito grandes ou muito pequenos.
- Conversão para tensores
- As imagens são convertidas para tensores, formato utilizado pelos frameworks de deep learning (TensorFlow, PyTorch).
- Estrutura típica: [batch_size, altura, largura, canais], onde canais = 1 (preto e branco) ou 3 (RGB).
-
Divisão de dados
O dataset já vem organizado em pastas train/, val/ e test/.
Atenção: o conjunto val/ dispõe de apenas 8 imagens para cada classe (total 16), o que é muito baixo para monitoramento confiável durante o treino. Isso pode levar a flutuações fortes nos valores de validação (val_accuracy / val_loss) ou dar uma falsa impressão de generalização.
Cada conjunto é mantido separado para:
Treinamento: ajuste do modelo.
Validação: monitoramento da performance e prevenção de overfitting.
Teste: avaliação final do modelo em dados nunca vistos.
- Data Augmentation (Aumento de Dados)
- Para combater overfitting e aumentar diversidade, aplicam-se técnicas de transformação aleatória:
- Rotação (ex.: ±15°).
- Translação (shift horizontal/vertical).
- Zoom.
- Flip horizontal.
- Essas transformações criam novas amostras sem precisar coletar mais imagens reais, ajudando o modelo a generalizar melhor.
- Para combater overfitting e aumentar diversidade, aplicam-se técnicas de transformação aleatória:
Considerações Importantes
- O pré-processamento não altera o conteúdo clínico das imagens; apenas facilita que o modelo aprenda padrões visuais de forma mais eficiente.
- Técnicas de data augmentation devem ser moderadas, pois exageros. podem gerar imagens irreais, prejudicando a aprendizagem.
- A padronização permite que o mesmo pipeline seja replicável em outros datasets ou projetos similares.
Treinamento e Validação do Modelo
Objetivo
O treinamento tem como objetivo ensinar o modelo a reconhecer padrões visuais presentes nas radiografias, distinguindo entre imagens normais e com sinais de pneumonia.
A validação permite monitorar o desempenho durante o treino, ajustando parâmetros e evitando overfitting.
Arquitetura Inicial Sugerida
Para o projeto, recomenda-se utilizar uma CNN simples ou transfer learning, por exemplo:
- CNN customizada:
- Camadas convolucionais + pooling + camadas densas finais.
- Ativação ReLU nas camadas ocultas.
- Saída sigmoid para classificação binária.
- Transfer Learning:
- Modelos pré-treinados como VGG16, ResNet50 ou EfficientNet.
- Apenas últimas camadas são treinadas para o dataset de pneumonia.
- Permite melhor performance com menor volume de dados.
Hiperparâmetros Importantes
- Batch size: 16 ou 32 (balanceando memória e performance).
- Epochs: 20–50, ajustando conforme evolução da loss.
- Otimizador: Adam, por sua capacidade de convergência rápida.
- Learning rate: 1e-4 como ponto inicial.
- Loss function: Binary Cross-Entropy (adequada para classificação binária).
Métricas de Avaliação
É essencial avaliar o modelo não apenas pela acurácia, mas também considerando métricas que refletem impacto clínico:
- Accuracy: % de acertos geral.
- Precision: importância de evitar falsos positivos (diagnóstico errado de pneumonia).
- Recall (Sensitivity): importância de evitar falsos negativos (pneumonia não detectada).
- F1-Score: equilíbrio entre precision e recall.
- ROC-AUC: desempenho geral do modelo em diferentes limiares.
Estratégia de Validação
- Validação durante o treino: monitorar a loss e a acurácia no conjunto de validação.
- Early Stopping: interrompe o treino quando não há melhora na validação, prevenindo overfitting.
- Model Checkpoint: salvar a versão do modelo com melhor performance.
Considerações Finais
- Treinar e validar o modelo dessa forma cria uma base sólida para testes interativos, permitindo que o cientista de dados compreenda onde o modelo acerta ou erra.
- Essa abordagem também prepara o terreno para futuros protótipos de aplicação clínica, respeitando sempre as limitações do dataset.
Teste Interativo e Validação Aleatória
Objetivo
Permitir que o cientista de dados ou usuário teste o modelo em imagens específicas, observando:
- Predição feita pelo modelo (NORMAL ou PNEUMONIA).
- Confiança da previsão (probabilidade).
- Comparação com o rótulo verdadeiro, quando disponível.
Essa abordagem aproxima o projeto da aplicação real, reforçando o caráter prático e didático do portfólio.
Funcionamento do Teste Interativo
- Seleção aleatória de imagem
- O script seleciona automaticamente uma imagem de qualquer pasta (test/ ou val/).
- Pode ser implementada uma função que escolha imagens com ou sem repetição para múltiplos testes.
- Predição pelo modelo
- A imagem é processada pelo modelo treinado.
- O modelo retorna a classe prevista e a probabilidade associada.
- Comparação com rótulo verdadeiro
- O script verifica a pasta de origem (NORMAL ou PNEUMONIA).
- Compara o resultado do modelo com o rótulo real.
- Exibe se o modelo acertou ou errou.
- Exibição de resultados
- Mostra a imagem selecionada.
- Indica a predição, probabilidade e rótulo verdadeiro.
- Pode ser feito um pequeno resumo estatístico se forem selecionadas várias imagens (ex.: taxa de acerto em N imagens aleatórias).
Benefícios dessa Abordagem
- Permite visualização imediata do desempenho do modelo em exemplos concretos.
- Facilita a interpretação dos resultados, conectando métricas abstratas (accuracy, precision, recall) a casos reais.
- Pode servir como base para protótipos de aplicação clínica, onde o médico carrega uma imagem e recebe a predição do modelo.
- Aumenta o caráter didático do portfólio, mostrando todo o ciclo de ciência de dados: desde o problema real, passando pelo modelo, até a validação prática.
Observações
- Este teste é educacional, e não substitui diagnóstico médico.
- Ideal para demonstrações, validação de modelo e aprendizado de técnicas de visão computacional.
- Futuras aplicações clínicas devem incluir campos de confirmação médica e seguir regulamentações de saúde.
Reflexão, Limitações e Próximos Passos
Reflexão sobre o projeto
- Este projeto demonstra todo o ciclo de ciência de dados aplicada a imagens médicas:
- Fundamentação científica para entender o problema.
- Escolha de modelo e técnicas adequadas.
- Pré-processamento dos dados.
- Treinamento e validação do modelo.
- Teste interativo em imagens individuais.
- A integração de cada etapa permite ao cientista de dados compreender o raciocínio por trás de cada decisão, fortalecendo o aprendizado e a replicabilidade do projeto.
Limitações do projeto
- Dataset limitado e desbalanceado
- Mais imagens de pneumonia que normais; é necessário cuidado para evitar viés do modelo.
- O conjunto de validação (val/) tem número muito pequeno de imagens (apenas 8 imagens em cada pasta), o que limita sua utilidade para monitoramento seguro de validação, tuning de hiperparâmetros e EarlyStopping.
- Qualidade das imagens
- Algumas radiografias podem ter ruído, sobreposição de estruturas ou baixa resolução, dificultando a generalização.
- Ausência de dados clínicos complementares
- Informações como idade, histórico médico ou sintomas não estão incluídas; o modelo se baseia exclusivamente na imagem.
- Não substitui avaliação médica
- O modelo serve como ferramenta de apoio educacional ou protótipo de aplicação. Diagnóstico final deve sempre ser confirmado por profissionais de saúde.
Próximos Passos
- Melhorias técnicas
- Aplicar ensemble de modelos para aumentar robustez.
- Testar arquiteturas mais avançadas (EfficientNet, DenseNet).
- Implementadas explainable AI (XAI) para interpretar decisões do modelo (o racional e código serão disponibilizados na versão avançada).
- Aprimoramento do dataset
- Coletar mais imagens normais para equilibrar classes.
- Incluir radiografias de diferentes hospitais, equipamentos e populações.
- Protótipo de aplicação
- Foi desenvolvida uma interface simples para upload de imagem e exibição da predição.
- Integra a função de visualização dos resultados, probabilidade e rótulo real para fins educacionais.
- Documentação didática
- Manter registros claros de decisões, parâmetros e resultados nesta página.
- Possibilitar replicação do projeto por outros cientistas de dados.
🩺 Diagnóstico de Pneumonia em Raio-X com Inteligência Artificial
A radiografia de tórax é um dos exames mais solicitados no mundo para avaliação de doenças pulmonares. Dentre elas, a pneumonia se destaca como uma das mais graves e comuns, exigindo diagnóstico rápido e preciso.
Com o avanço da Inteligência Artificial, especialmente das redes neurais convolucionais (CNNs), tornou-se possível treinar modelos capazes de identificar padrões radiológicos sutis com alto grau de acerto.
Este projeto demonstra como um modelo de IA pode ser aplicado ao diagnóstico automático de pneumonia a partir de imagens de raio-X, utilizando redes neurais profundas e explicabilidade visual (Grad-CAM).
🌐 Versão online da aplicação
Agora o projeto está disponível em versão interativa e online, hospedada no Render.com.
A demonstração permite que o usuário envie uma radiografia própria ou selecione uma das amostras do sistema, recebendo em tempo real o diagnóstico estimado e a visualização explicativa do modelo (Grad-CAM).
🔗 Acesse a aplicação: https://pneumonia-demo.onrender.com
Obs.: ao chegar no site aguarde alguns minutos até o Render provisionar os serviços da aplicação.
⚙️ Arquitetura atualizada da solução
A arquitetura do projeto foi completamente reestruturada para permitir o deploy em ambiente de produção com front-end e back-end integrados.
Componentes principais:
- Frontend: desenvolvido em React (Vite), responsável pela interface do usuário, upload das imagens e exibição dos resultados.
- Backend: implementado em FastAPI, contendo o modelo TensorFlow Lite e os endpoints REST de predição.
- Modelo de IA: versão compacta em TensorFlow Lite (TFLite), otimizada para desempenho em CPU.
- Hospedagem: deploy no Render.com via container Docker, com build automatizado a partir do repositório GitHub.
Fluxo resumido:
- O usuário envia uma imagem de raio-X ou escolhe uma das amostras.
- O frontend envia o arquivo ao endpoint
/predictvia requisiçãoPOST. - O backend processa a imagem, realiza a inferência e gera o mapa Grad-CAM.
- O resultado é retornado em JSON, incluindo o diagnóstico, a confiança e as URLs das imagens original e explicada.
- O React exibe ambas as imagens lado a lado, em tempo real.
💡 Explicabilidade e Grad-CAM
A inclusão da técnica Grad-CAM (Gradient-weighted Class Activation Mapping) foi fundamental para aumentar a interpretabilidade do modelo.
O mapa de calor gerado permite visualizar quais regiões da radiografia contribuíram para a decisão da rede, evidenciando o raciocínio interno do algoritmo.
Na versão atual hospedada, o Grad-CAM foi implementado de forma otimizada, com filtros Gaussianos e sobreposição dinâmica sobre a imagem original.
🧠 Modelo e desempenho
O modelo TFLite empregado foi treinado sobre um conjunto de radiografias públicas contendo classes Normal e Pneumonia.
Após a conversão e calibração, a versão reduzida mantém uma acurácia aproximada de 90%, acertando 9 de 10 amostras de teste, conforme demonstrado na aplicação online.
Por se tratar de uma versão compacta, o desempenho é balanceado para priorizar velocidade de resposta e portabilidade em detrimento de profundidade de rede.
⚙️ Desafios técnicos do deploy
Durante o desenvolvimento da arquitetura de produção, alguns desafios técnicos foram enfrentados e superados:
- Ajuste das rotas de arquivos estáticos e temporários (samples / temp);
- Geração dinâmica de URLs baseadas no domínio público (em vez de localhost);
- Correção de CORS e integração entre React e FastAPI;
- Limitação de recursos do plano gratuito do Render (cold start, timeout e memória);
- Conversão e teste do modelo TensorFlow → TensorFlow Lite.
Essas etapas garantiram a estabilidade da aplicação e a compatibilidade entre os ambientes local e remoto.
🧭 Considerações finais
Este projeto reforça o poder da Inteligência Artificial aplicada à área da saúde e mostra como modelos explicáveis podem auxiliar profissionais e estudantes na interpretação de exames.
Importante: trata-se de uma aplicação educacional e demonstrativa, sem uso clínico real.
O objetivo é inspirar pesquisadores, estudantes e desenvolvedores a compreenderem o potencial e os desafios da IA em diagnósticos médicos.
Deixe um comentário